
TL;DR
Expecting even a well-trained neural net to character-by-character generate text with any semantic content is ambitious. Building and training this LSTM is more didactic than deployable, but we’ll weaponize it anyway.
All this code is in a github repo
R, Keras, and Twitter
I hadn’t had the opportunity to explore RStudio’s API into Keras, a sensible neural network abstraction backed by many lower-level providers such as CNTK, Theano, and Tensorflow. Generating text is fun, and a few year ago, Andrej Karpathy explained how to create a NN to do just that. RStudio has a tutorial for text generation; Julia Silge took it a bit further and I aimed to stand on those shoulders.
But I needed a corpus from which to train.
Twitter seemed like a good place to start, and, frankly, only one Tweeter has the bigliest tweets: [@realDonaldTrump](https://twitter.com/realDonaldTrump). He is prolific, has a large following, and opinionated. And, the Trump Twitter Archive exists, which made getting the past tweets a breeze.
The Tweets
library(jsonlite)
library(lubridate)
library(readr)
library(purrr)
library(dplyr)
urltxt <- c("https://github.com/bpb27/trump_tweet_data_archive/raw/master/condensed_2016.json.zip",
"https://github.com/bpb27/trump_tweet_data_archive/raw/master/condensed_2017.json.zip",
"https://github.com/bpb27/trump_tweet_data_archive/raw/master/condensed_2018.json.zip")
zipped_json_to_df <- function(url) {
temp <- tempfile(fileext = ".zip")
download.file(url,temp)
data<- fromJSON(read_file(temp))
unlink(temp)
data
}
trump_df <- map_df(urltxt, .f=zipped_json_to_df) %>%
mutate(created_at = parse_date_time(created_at, orders="%a %b! %d! %H!:%M!:S! %z!* Y!")) %>%
rename(status_id = id_str) %>%
rename(reply_to_user_id = in_reply_to_user_id_str)
write_csv(trump_df, "./data/trump_df.csv")That code reaches into the Trump Twitter Archive (“TTA”) and pulls in the tweets from 2016 through 2018. I had to handle the ZIP’ed archives and an expressive datestamp, but the TTA made getting history a breeze.
After the history, I can keep up-to-date via the rtweet package, helpfully hosted on github.com and well-documented. The code to do so follows; it mostly reads in the archived trump_df.csv, finds the most recent tweet in the archive and uses the Twitter API to pull in the tweets after the most recent one.
library(rtweet)
library(readr)
library(dplyr)
handle <- "realDonaldTrump"
devtools::load_all("./packages/tweetlstm/")
credsFile <- "creds.csv"
if (file.exists(credsFile)) {
creds <- read_csv(credsFile)
} else {
stop("Need credentials")
}
token <- initialize_twitter(creds)
trump_df <- read_csv("./data/trump_df.csv") %>%
mutate(status_id = as.character(status_id)) %>%
mutate(reply_to_user_id = as.character(reply_to_user_id))
most_recent = trump_df %>% arrange(created_at) %>% pull(status_id) %>% last()
timeline <-
get_timeline(user = handle, n = 3200, since_id = most_recent)
if (nrow(timeline) > 0) {
trump_df <- trump_df %>%
bind_rows(timeline %>% select(colnames(trump_df))) %>%
distinct(status_id, .keep_all = TRUE)
}
write_csv(trump_df, "./data/trump_df.csv")At the completion, the trump_df.csv will contain up-to-date tweets.
Project Structure
You’ll note that the “read twitter” code above uses devtools::load_all(...) to load an R package. I’m trying to structure my R code in resuable artifacts, and in R, that means R packages. I struggled with a sensible directory structure that would allow me to create and maintain application- and package-code with minimal overhead (e.g. creating an independent R package and associated repo for code that will live only in a specific project / application seemed onerous). Research (well, internet search) showed some folks (I lost the link) were putting project-specific packages into a packages directory inside the project folder. Brilliant. The code in the github repo is laid out like:
├── alphabet.RDS
├── creds.csv
├── data
│ ├── trump_df.csv
├── generate_reply.R
├── getData.R
├── model_history.RDS
├── packages
│ └── tweetlstm
│ ├── data
│ ├── DESCRIPTION
│ ├── man
│ ├── NAMESPACE
│ └── R
│ ├── model_management.R
│ └── twitter_managment.R
├── README.md
├── train_model.R
├── trumprnn.h5
├── trump-rnn.Rproj
└── update_tweets.RThe .R code at the top level is the application code. The .R code down under packages is code that comprises the application-level packaging of common functions.
I’m embarrassed that it took me this long to trip over this concept. (I’ll pressure test this for a bit and I’m sure I’ll tweak it)
Dude, where are the LSTMs?
Way down in the twitterlstm package, in the model_management.R code, lives this function:
create_model <- function(chars, max_length){
keras_model_sequential() %>%
bidirectional(layer_cudnn_lstm(units=256, input_shape = c(max_length, length(chars)))) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(length(chars)) %>%
layer_activation("softmax") %>%
compile(
loss = "categorical_crossentropy",
optimizer = optimizer_adam(lr = 0.001)
)
}This function creates the model. It is very close to Julia’s (and RStudio’s), but there are a couple of differences:
- The LSTM is wrapped in a
bidirectionalwrapper. This effectively duplicates the LSTM layer, and feeds the input sequence backwards to the duplicated layer. The result has context for both the past and future around the current time step. - A
layer_dropouthas been introduced. Dropout randomly removes neurons from the network during training, which removes signal. Turns out,dropoutis a pretty effective way to ensure that the net does not overfit on the training data, because during training (and at each step), only some (randomly selected) data is available. - The LSTM is a
layer_cudnn_lstm. A year ago, I built my own deeplearning box, around which is a CUDA-capable nVidia GPU. Alayer_cudnn_lstmis purpose-built to take advantage of these. In my case, I am able to train in 1/4 of the time compared to a “regular”layer_lstm. If you have the means, I highly recommend one of these.
The code to train the network is in the train_model.R file, reproduced here:
library(keras)
library(tidyverse)
library(tokenizers)
library(lubridate)
library(ggplot2)
devtools::load_all("./packages/tweetlstm/")
max_length <- get_max_length()
trump_df <- read_csv("./data/trump_df.csv")
text <- trump_df %>%
filter(!is_retweet) %>%
arrange(created_at) %>%
top_n(3300, created_at) %>%
clean_and_tokenize()
print(sprintf("Corpus length: %d", length(text)))
alphabet <- text %>%
unique() %>%
sort()
saveRDS(alphabet, file = "alphabet.RDS")
print(sprintf("Total characters: %d", length(alphabet)))
vectors <- get_vectors(text, alphabet, max_length)
model <- create_model(alphabet, max_length)
model_history <- fit_model(model, vectors, epochs = 40, view_metrics = FALSE)
saveRDS(model_history, "model_history.RDS")
model %>% save_model_hdf5("./trumprnn.h5")It loads the application package, loads the archive of tweets, tokenizes 3300 of the most-recent tweets (which is a little over a year), prints out some statistics, vectorizes the text, and then fits the model (which returns a model_history object).
Model fitting looks like:
fit_model <- function(model, vectors, epochs = 1, view_metrics = FALSE){
model %>% fit(
vectors$x, vectors$y,
batch_size = 32,
epochs = epochs,
validation_split= 0.1,
#callbacks = list(callback_early_stopping(patience= 4)),
view_metrics = view_metrics
)Which is not too different from prior code; about the only new thing is the validation_split argument, which allows for epoch-level validation on 10% of the data. We can see this with the model_history:
library(keras)
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(ggplot2)
library(ggthemes)
# ignore this hard-coded path; it is just for the blog
readRDS('~/projects/github.com/trump-rnn/model_history.RDS') %>%
plot() +
scale_color_few(palette = "Dark") +
scale_fill_few(palette = "Dark") +
theme_few() +
labs(
title = "Model Validation",
caption = "256 Node Bidirectional LSTM\ntrained on @realDonaldTrump tweets"
)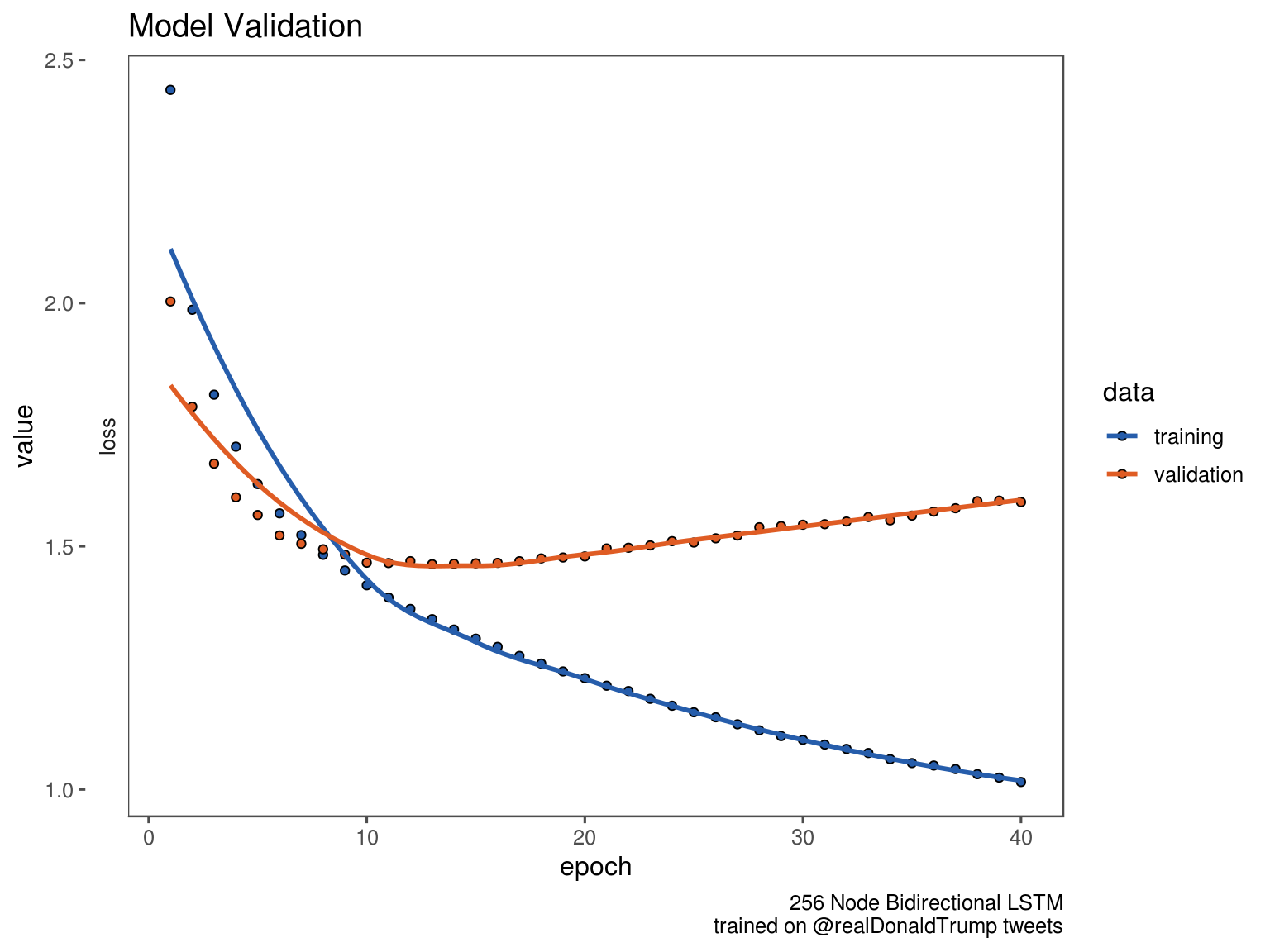
The diverging lines indicate that, despite the layer_dropout, we’re still overfitting. That’s probably a whole new blogpost. For this blog, at epoch 40, we have a fitted model.
Generate some text
That’s easy, just call tweetlstm::generate_phrase :
generate_phrase(
model,
trump_df %>%
top_n(n = 5, wt = created_at) %>%
clean_and_tokenize(),
alphabet,
max_length,
230,
0.5
)The generate_phrase function takes a model, the array of characters for the seed text, the list of symbols - the alphabet - from which to sample characters, the number of characters to actually form the seed, the total number of characters to generate, and a number to control how aggressive the model should be when it selects the next character. Julia explains it much better than I could. When you call this, you (might) get something like:
ate and hosting they want to stop the political policies, she was the story of
the Fake News Media is the one of the highly condrouse of the Russian First
Country are provides that the Wall to the @WhiteHouse! #Mor
ck to the United States because there was no Collusion in the Trump Campaign back
on the Democrats look at the House and to the Dossier, the Trump Agenday to which
the supporting countries to fire the U.S. and CoNot exactly sensible. Not even covfefe-level sensible. But, focus on what it can do. “United States”, “Fake News Media”, and even “@Whitehouse” were all generated character-by-character from a NN model trained on a corpus of tweets. That’s amazing. It is not exactly deployable-level amazing, but that’s not going to stop me.
Weaponize It
We have a model and I’d rather not have it sit on the shelf and depreciate. What to do. What. To. Do?
Hey, maybe everytime @realDonaldTrump tweets, this thing can tweet back? The rtweet package can POST as well as it can GET… I needed to create a new Twitter account (a bot oh noes), which I did, and then created an authorized application connected to that account.
And the generate_reply.R file will do exactly what it says it will do: it generates a reply:
library(rtweet)
library(readr)
library(dplyr)
library(keras)
handle <- "realDonaldTrump"
devtools::load_all("./packages/tweetlstm/")
credsFile <- "creds.csv"
if (file.exists(credsFile)) {
creds <- read_csv(credsFile)
} else {
stop("Need credentials")
}
token <- initialize_twitter(creds)
my_replies <- get_timeline(rtweet:::home_user()) %>%
#filter(reply_to_screen_name == handle) %>%
arrange(created_at)
trump_df <- read_csv("./data/trump_df.csv") %>%
mutate(status_id = as.character(status_id)) %>%
mutate(reply_to_user_id = as.character(reply_to_user_id))
# if my replies are all before the last non-retweet entry from handle, then I need to
# reply. If not, then I can sleep and wait for a new tweet.
my_last_reply_timestamp <- my_replies %>% top_n(n=1, wt = created_at) %>% pull(created_at)
the_unreplied_tweets <- trump_df %>% filter(!is_retweet) %>%
filter(created_at > my_last_reply_timestamp) %>%
arrange(created_at)
if(nrow(the_unreplied_tweets) > 0) {
reply_to_status_id <- the_unreplied_tweets %>% top_n(n=1, wt = created_at) %>% pull(status_id)
num_reply_chars <- 0
n_tweets <- 1
while (((num_reply_chars < max_length) && n_tweets <= 10)) {
reply_to_txt <- trump_df %>% top_n(n = n_tweets, wt = created_at)
reply_chars <- reply_to_txt %>% clean_and_tokenize()
num_reply_chars <- length(reply_chars)
n_tweets <- n_tweets + 1
}
if (num_reply_chars >= max_length) {
tweet_prefix <- paste0(".@", handle, ":")
model <- load_model_hdf5("./trumprnn.h5")
alphabet <- readRDS(file = "./alphabet.RDS")
the_reply <- generate_phrase(
model = model,
seedtext = reply_chars,
chars = alphabet,
max_length = get_max_length(),
output_size = 230 - nchar(tweet_prefix),
diversity = 0.4
)
the_reply <- paste(tweet_prefix, the_reply)
post_tweet(status = the_reply, in_reply_to_status_id = reply_to_status_id)
}
}The “action” line is that last one: post_tweet. It will reply to the most recent tweet from @realDonaldTrump with content seeded by the his most recent tweets and generated by the most recent version of the trained model.
I could wrap the three main files in a crontab so that on a periodic basis, the tweet archive is updated, the model is retrained, and any given tweet is replied-to (heck, webhooks might be able to help out here). I could do this. But I haven’t.
Next Steps
I probably need to try to generate more sensible tweets. I think this guy has some ideas I’ll want to try out.